
OpenClaw is Personal SuperIntelligence and Web 3.0
We are in the middle of a generation jump from Web 2.0 to Web3.0 (and no it has nothing to do with crypto)

First two months of 2026 (we are yet to end Feb!) felt like watching a garage band go stadium in 10x fast forward. A few weeks earlier most people had not heard of Peter Steinberger's ClawdBot; then it exploded, got renamed 2x to MoltBot and then to OpenClaw within a week, and suddenly the repo was sitting above 200k stars, got covered The Register and shot up to first place on OpenRouter's rankings Overnight, the hype turned into real numbers: OpenClaw at the top by token usage, ahead of coding agents like Kilo and Cline who have been holding the spot for months! You could almost hear every "just another AI wrapper" take aging in dog years.
By February 2026, the plot upgraded from hacker lore to boardroom drama. On February 14, 2026, Steinberger wrote that he had spent the week in San Francisco talking with major labs before deciding to join OpenAI; on February 16, the move was all over the tech press in Steinberger’s post, The Register, and The Verge. From the outside, it looked like the same talent-and-product tug-of-war that has been building between OpenAI and Meta, but I am happy that the open source project finds a home under a foundation as noted in Steinberger’s post
Meta, by the way already was on a trajectory towards this vision of personal agents. On December 29, 2025, Manus announced it was joining Meta, framing it as acceleration for personal AI agents in Manus’s own announcement and The Verge’s coverage. Manus is impressive too, but it is built upon a completely different premise, closed, locked down, way more security focussed, and designed for enterprise and ‘normies’ to safely start using from day one. But that also means it is not hackable, not something you can run on your miniPC, nor infinitely extendable.
In all this hullabaloo, we may have missed one big shift: Both open source tools like OpenClaw and products like Manus feels like the first mainstream taste of a read-write-execute web, where your primary interface is an agent that can actually do things on your behalf. Call it “Web 3.0” if you want, with one delicious irony: we are using that label for Peter’s project even though he has repeatedly told the crypto-”Web3” crowd to stop harassing him for token launches, as Protos reported and in his own X post. History has jokes, and this one is on-brand.
I may be reading too many tea leaves here, but to me it feels we are at the turn of a generation for 'the web', even if we do not realise it right away. But when I try to answer the question "what category is OpenClaw", it automatically comes from that question. Just look at its Github Star history - not that it means anything but the only things this popular are usually operating systems, programming languages and web frameworks. And OpenClaw is neither of this right? But what if it is? A 'web' framework, but for a very different generation of web!
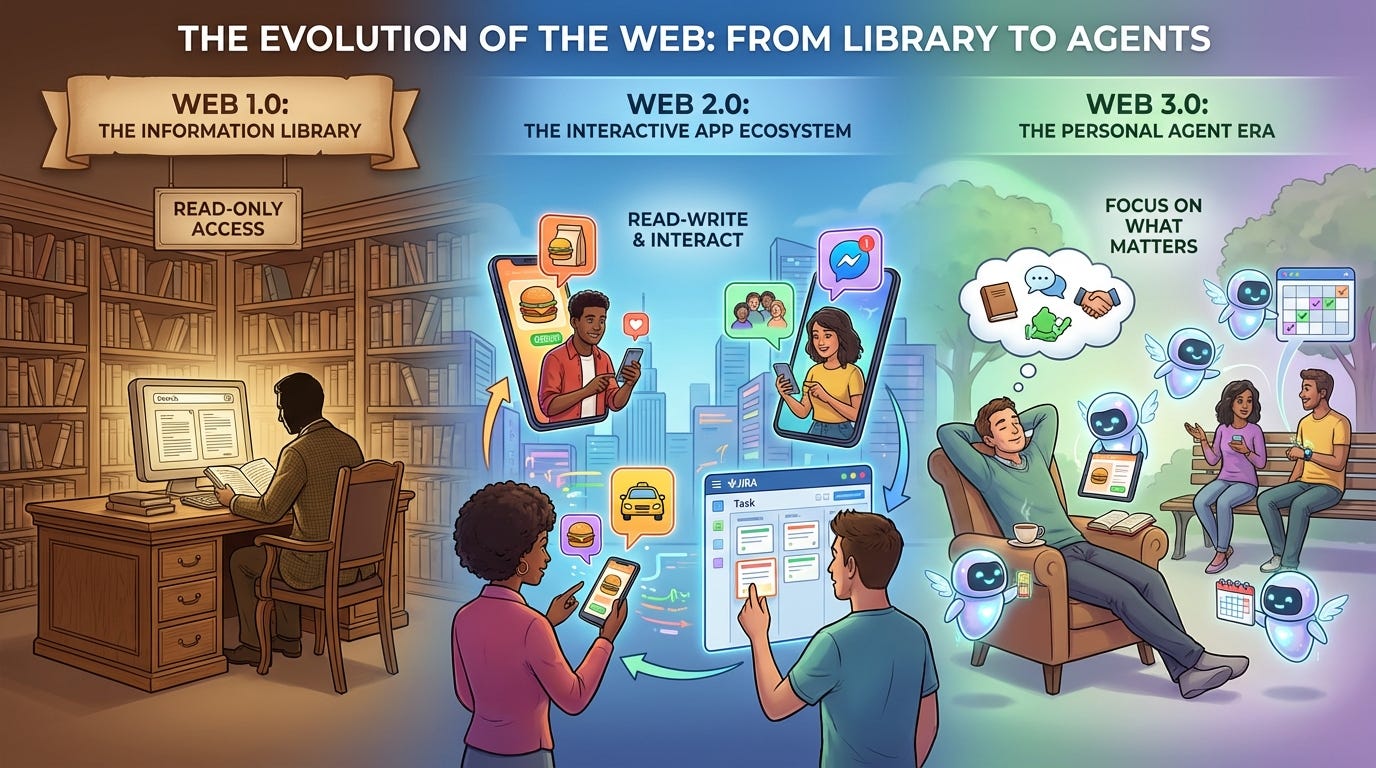
The Three Generations of the Web
To categorize OpenClaw properly, I want to look at the history of the web through the lens of data and interaction. The term “Web 3.0” got hijacked by the cryptocurrency era, but its lineage belongs to the Semantic Web, a “web of data” vision led by the W3C in the Semantic Web Activity, reflected in Semantic Web (Wikipedia), and in Berners-Lee’s Linked Data note.
The simplest framing is read → read-write → read-write-execute. Each era widens what a user can do, and each builds on the prior one rather than erasing it.
Web 1.0: The Static Library (1990–2004)
The first era of the web is often characterized as the “read-only” web, a digital archive of static information. In this period, communication was one way, from the author to the reader. Most consumers reached the web from desktop browsers and simply consumed pages rather than changing them. The dominant mental model was “sites” you visited with a browser, not applications you lived inside.
Web Entities: The core pair was site + client. If you wanted to publish information, you created a site; if you wanted to consume information, you used a browser as the client. The dominant interaction pattern was retrieval, usually via
GETrequests for representations of resources, as outlined in MDN’s client-server overview, MDN’s GET method, and RFC 9110. In that sense, Web 1.0 built large shared systems of information, as described in W3C Web Architecture.Architecture: Content was stored as static HTML files. Publishers updated their sites via FTP.
Interaction: Users were passive consumers. If you wanted to “interact,” you clicked a hyperlink to another static page. Web 1.0 is commonly defined in the Web 2.0 Wikipedia article as an era where content creators were few and most users were consumers of static pages. Interaction was primarily between publisher and reader, mediated by the browser.
Open vs. Closed: In this era, the “Open” route was self hosting an Apache HTTP Server on your own hardware, giving you full control. The “Closed” alternative was providers like GeoCities, which offered ease of use but siloed your content under their domain and terms (”renting a home”). For background on this era framing, see Web 1.0 (Wikipedia) and research on Web 1.0 vs 2.0 differences.
The desktop browser era matters here. The web’s early growth was driven by general purpose browsers like Mosaic and Netscape, and by the late 1990s Internet Explorer dominated the desktop browser market for years, as documented in the History of the World Wide Web. The primary UX was the browser window, and the primary unit of experience was the site.
Web 2.0: The Social Database (2004–2025)
The second era, popularized by Tim O’Reilly, shifted the focus to the “read-write web,” the participatory web where the user can become the creator.
Web Entities: The model expanded to database + API + app. The database became the primary store (SQL, NoSQL, and everything in between), the middle tier implemented business logic and exposed API calls, and the app (web or mobile) became the user-facing surface in classic IBM three-tier architecture and multitier architecture. This pattern is why Web 2.0 systems became strong systems of record, as described by IBM’s definition of system of record.
Architecture: Sites became dynamic platforms powered by the CRUD pattern and massive, centralized databases. The web became a platform for applications rather than static documents in the Web 2.0 framing.
Interaction: Interaction was no longer between publisher and reader, but between users. On Facebook or JIRA, you interact with others through a shared database row. “Write” unlocked user-to-user interaction and gave rise to platforms whose core value is orchestrating exchanges rather than publishing themselves. Platforms are intermediaries that enable interactions between distinct groups of users (a two-sided or multi-sided market), which explains why marketplaces and social platforms scaled so fast in two-sided markets and the platform economy.
Open vs. Closed: The “Open” version of Web 2.0 meant using platforms like WordPress or Ghost, where you owned the database and the code. The “Closed” version involved blackbox platforms like Medium or Substack, where the provider managed the infrastructure and your data was a row in their table.
This is where “apps” became the dominant UX. A web application is software delivered through the browser, often backed by multi tier services that build responses dynamically and store state in centralized systems. The front end might feel like a single app, but behind it is an ecosystem of APIs and distributed services. Web APIs expose endpoints over HTTP, typically in JSON or XML, and became the connective tissue between systems and services. In practice, many apps also keep local state and synchronize with backend APIs periodically, especially in offline-first mobile patterns like Android’s offline-first architecture. This app-api-database loop is what let platforms like Google Workspace, Jira, Twitter, Facebook, Uber, and Airbnb become networked systems of record and participation at internet scale.
Web 3.0: The Agentic Orchestrator (2025–Beyond)
We are now entering the “Read-Write-Execute” era, where the web is no longer just a place to read or write, but a place to perform work via agents that can call tools, move data, and take actions. You are not just browsing sites anymore, you are delegating to a process that browses on your behalf. The building blocks are becoming standardized: tool and function calling, agent frameworks, and tool connectivity standards like MCP in the Anthropic announcement and the MCP docs. For a solid overview of the canonical agent loop, planning, memory, and tool use, see Lilian Weng’s survey on LLM Powered Autonomous Agents.
We can also trace the recent surge in tool using agents through “reasoning + acting” systems like ReAct, which helped popularize the loop of thinking, using tools, and iterating.
Web Entities: The new entity on the block is the agent, and in practice it introduces two more entities around it: an orchestrator and a compute node (filesystem + CPU + memory + network) where long-running, tool-using workflows can execute and resume, as shown in LangGraph durable execution, OpenAI Operator, and OpenClaw architecture.
Architecture: The focus shifts from centralized databases to personal nodes of compute. A Web 3.0 entity needs a filesystem and a CPU, a “scratchpad” and compute power in a box.
Interaction: Agents and Orchestrators become first-class citizens. You no longer interact directly with every website; your orchestrator does. Agents can interact with Web 1.0 sites (read), Web 2.0 apps/APIs (transact), and increasingly with other Web 3.0 agents over interoperable protocols like A2A specification or just API-to-MCP-to-CLI wrappers, (refer GitHub project, and Google’s A2A announcement). A practical near-term example is your personal admin agent negotiating with a company support agent for refunds, reschedules, or exceptions before either side escalates to a human, like the service-agent direction described by Salesforce.
Agents vs. Orchestrators: It is crucial to distinguish between the two. Agents like Goose or OpenCode are specialized tools for specific tasks, like coding. Orchestrators like OpenClaw, OpenHands, CrewAI, LangGraph, or Microsoft AutoGen are the conductors. They manage multiple agents, share context, and coordinate complex workflows toward a common goal.
Open vs. Closed: We see this dichotomy again. The “Open” path is the OpenClaw model, DIY setup on your own persistent compute (VPS), giving you full “shell” access to the environment. The “Closed” path is represented by providers like Manus AI, which offer a blackbox, hosted agent experience where you have no access to the underlying execution environment.
In Web 3.0, agents become the UX layer. Instead of clicking through app UIs, you delegate to an agent that orchestrates the workflow and calls the underlying interfaces: APIs, CLIs, or MCP servers. MCP is explicitly designed to connect AI applications to tools, data sources, and workflows, acting as a standardized connector for these integrations in the MCP docs and the Anthropic MCP announcement. The web is still full of Web 2.0 services, but your primary interface becomes the agent that can reach them through their public APIs or command line tools.
The Rise of Personal Superintelligence
The phrase Personal Superintelligence is still young, and the most concrete public articulation comes from Mark Zuckerberg’s July 30, 2025 letter, where he argues that superintelligence should arrive as a personal extension that increases individual agency rather than a distant utility owned by institutions, as outlined in Meta’s letter, CBS News coverage, and a Business Insider summary. In that letter he defines the everyday shape of the idea, writing that a personal superintelligence should “help you achieve your goals, create what you want to see in the world, experience any adventure, be a better friend to those you care about, and grow to become the person you aspire to be,” in his Meta letter. The same document ties the concept to a form factor thesis, predicting that personal devices like glasses that can see and hear what we do will become primary computing devices, which implies a continuous companion rather than a sporadic chatbot, in both the Meta letter and CBS News coverage.
Press coverage repeats the human centric framing and emphasizes the infrastructure required to make it real, with Tom’s Hardware describing the goal as building AI that feels “like an extension of yourself” and noting the hardware stacks needed to deliver it at scale. The term itself remains concentrated around Meta’s messaging, which matters because it suggests that “personal superintelligence” is not yet a settled industry category but a specific thesis about control, agency, and interface, backed by the claim in the Meta letter that the coming decade decides whether superintelligence becomes a tool for personal empowerment or a force that displaces large swaths of society.
Sam Altman has been explicit, in the context of Steinberger joining, about “very smart agents” interacting to do useful work for people, as quoted by The Register. On the product side, OpenAI’s developer framing leans into this direction with agent workflows that emphasize tool use, memory, and orchestration in the OpenAI Agents docs, which is the technical substrate you would need if “personal” is meant to imply durable context and delegated action rather than a one shot chat session.
New Things Are Built on Old Things
Just to be clear, it is not like Web 2.0 replaced or wiped out Web 1.0. We still read static pages, even if we discover them via search and social feeds. Paul Graham and Joel Spolsky’s blogs will remain timeless artifacts on the web. The same pattern is likely here. Web 3.0 will not replace Web 2.0 any time soon, it will expand and augment on top of it. Agents will sit on top of apps, and the apps that are easiest to script through APIs and CLIs will have an edge. The rest will feel like old malls with no doors.
If you want a quick mental model, Web 1.0 gave us sites, Web 2.0 gave us apps, and Web 3.0 gives us agents on top of those apps. For publishing, the clearest shift from Web 1.0 to Web 2.0 is a static personal blog turning into a platform-native publication on something like Substack or Medium: drafts, subscribers, comments, payments, distribution, all inside one product.
What does not change is reading itself. A good essay is still a good essay. What changes in the Web 3.0 layer is discovery and curation: an agent can look at your recent activity, inspect your newsletters through Gmail, cross-check your day against your calendar, and re-rank your reading queue from Readwise for what matters today.
Travel is an even cleaner Web 2.0 to Web 3.0 story. Web 2.0 already gave us powerful specialist services and APIs for flights, for hotels, for rides, and for scheduling. A Web 3.0 agent does not replace those systems; it composes them, searching flights, reserving stays, booking the airport ride, dropping the itinerary into your calendar, and reshuffling the plan when something slips.
Agents as Web Entities
The web does not only mean ‘web’sites (it hasn’t been for a while, although we continue to use the term colloquially). If you map the generations by their dominant entities, the sequence becomes clearer:
Web 1.0: site + client (browser) gave us systems of information.
Web 2.0: database + API + app gave us systems of record and participation.
Web 3.0: agent + orchestrator + compute node gives us systems of action.
In Web 1.0, a web entity needed storage for HTML. In Web 2.0, it needed a database and service layer (and often a smart client to store some frontend app state). In Web 3.0, it needs a scratchpad plus compute. That is why the filesystem and CPU matter. You are no longer just storing data. You are running a process that can read, write, and execute on your behalf.
From Accounts to Agents: How to ‘exist’ on the Web
In the Web 2.0 era, being a resident meant maintaining a collection of Accounts. If you wanted a job, you made an account on LinkedIn. If you wanted a cab, you made an account on Uber. If you wanted to book travel, you made an account on Booking.com. Each account was a static profile siloed within a platform’s database. But you owned some ‘data’ connected to that account, as you kept using the service your data increased. It was your data, even though the platform is usually the custodian of it.
In the Web 3.0 era, residency is defined by Agents. Instead of (not really instead of, more like in addition to) logging into a dozen platforms, you maintain a persistent compute node, essentially your own personal VPS or “always alive” compute box.
This node is the home for your orchestrator. You do not necessarily have a separate box for every task. Instead, your primary agent functions as a conductor, spawning subagents to handle specific workflows and terminating them once the job is done, for example the architecture shown here in AutoGen AgentChat docs.
This represents a fundamental shift from “Software as a Service” to “Software as Labor”. You are no longer just owning data. You are owning a remote execution environment that is continuously active. Your residency on the internet is defined by the compute power you command and the agents that live within it.
First-Class Citizens of the Internet
The Web has always had software agents, as W3C Web Architecture explicitly notes: browsers, crawlers, proxies, and servers are all agents in the system. But those were mostly deterministic workers, excellent at what was hardcoded and brittle outside it. What changes now is LLM-powered agency: systems that can reason about next steps, choose tools, recover from dead ends, and continue toward a goal in ambiguous environments, as seen in the ReAct paper, LLM Powered Autonomous Agents, and OpenAI’s ChatGPT agent announcement.
The infrastructure is finally catching up to that behavior. MCP (November 25, 2024) gives a common interface for tools and data in the Anthropic MCP announcement and MCP docs, A2A (April 9, 2025) gives a path for agent-to-agent interoperability in Google’s A2A announcement and the A2A spec, and product launches like OpenAI Operator and ChatGPT agent turned the idea from lab demo into everyday UX.
It is still worth being precise about language. “Web3” in popular usage usually points to crypto in Web3 (Wikipedia); “Web 3.0” historically pointed to interoperability and machine-readable semantics in W3C Semantic Web Activity. The agentic model is closer to that older lineage: open standards, portable context, and software acting on your behalf across systems.
That is why it feels fitting that this chapter is being turned by Peter Steinberger. In his own words, he is “a builder at heart,” a line also echoed by The Register. And during the rename chaos, he was blunt with token promoters and impersonators: he said he would never launch a coin and asked the crypto crowd to stop harassing him, as covered by Decrypt, Protos, and his own X post. If Web 3.0 is becoming the read-write-execute web, this is the poignant part: a builder is pulling the term back from speculation theater and returning it to software that actually does useful work.